Track Reconstruction with GPU Acceleration
Development of GPU-accelerated track reconstruction algorithms for high-energy physics experiments at CERN’s Large Hadron Collider (LHC).
Background
The High-Luminosity LHC will produce unprecedented amounts of collision data, requiring advanced algorithms to reconstruct particle trajectories in real-time. Standard rule-based tracking algorithms which run on the GPU will not be able to handle this huge increase in data. Thus, a GPU-version of these algorithms has been implemented. However, running this GPU algorithm at scale is not trivial. Enter GPU tracking as-a-Service which decouples the inference from the rest of the reconstruction algorithm. This provides a simle and scalable solution for running tracking algorithms at the future HL-LHC.
Objectives
- Accelerate track reconstruction algorithms using GPUs
- Implement inference-as-a-service architecture
Technical Approach
Rather than directly coupling CPU and GPU on the same node, we implement a coprocessor-as-a-Service (aaS) paradigm that separates the GPU algorithm onto a dedicated GPU server as shown below:
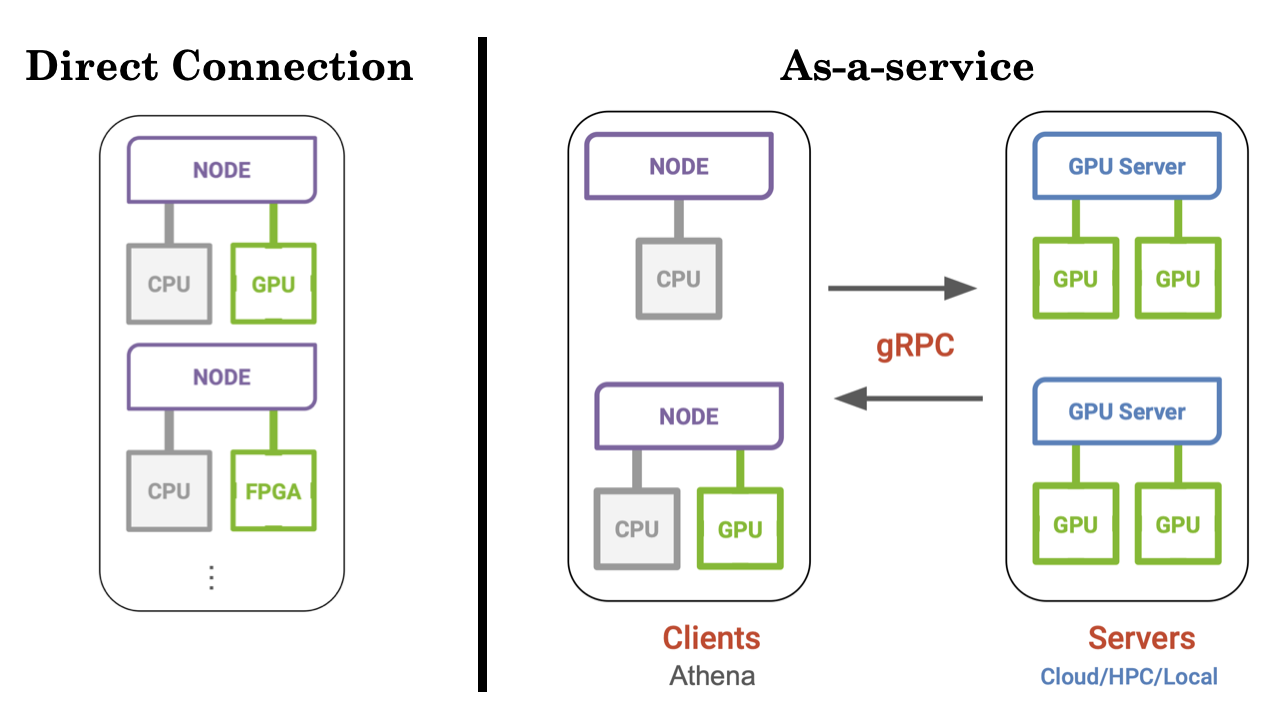
Comparison of Heterogeneous Computing (Direct Connection) and GPU as a Service paradigms. Direct connection couples CPU and GPU on the same node, while as-a-Service separates the GPU algorithm to a dedicated GPU server.
This approach offers several key advantages:
Motivation:
- Heterogeneous computing can result in inefficient GPU utilization when many CPU processes cannot fully occupy a single GPU, or when a GPU algorithm cannot fully occupy a GPU even with concurrent CPU processes
- Traditional integration of complex GPU code into production frameworks like ATHENA is challenging and requires tight coupling
- Industry-proven containerization and backend approaches for serving machine learning models can be applied to particle tracking
Implementation: We use the Triton Inference Server as our backend framework, with a custom C++ backend wrapping the TRACCC algorithm. This architecture provides:
- Multiple concurrent instances of the GPU backend on a single device
- Dynamic management of client requests from single or multiple sources
- Minimal data exchange between client and server via gRPC protocol
- Complete decoupling of CPU and GPU components, enabling seamless integration into production frameworks
Client Integration: We have developed an ATHENA client to interface with our backend, with no direct dependencies on TRACCC—all TRACCC dependencies are compiled within the container image. The modular design allows future integration with other track finding algorithms by simply changing the ingress point, and supports flexibility in switching between different tracking pipelines.
Expected Results
This GPU as a Service approach enables several key improvements:
- Enhanced GPU Utilization: Multiple model instances can be loaded onto a single GPU, overcoming the latency overhead introduced by the service architecture
- Scalability: The infrastructure scales gracefully by increasing concurrent requests and model instances without requiring CPU modifications
- Future Performance Gains: Less memory-hungry versions of TRACCC will enable significantly more model instances per GPU, approaching full GPU compute saturation
- Production Ready: The architecture provides a scalable and reliable path for deploying GPU-accelerated particle tracking within production frameworks
Resources
- GitHub Repository
- CERN Presentation
- Simple Triton demonstrator, runs on NVIDIA and AMD hardware.